(注:由于现在域名全都要备案了,**.tech** 域名不让备案,下面的nladuo.tech统一更改为nladuo.cn)
说说HTTP请求:GET与POST
在上一节中,我们在不知道原理的条件下调用了requests.get方法下载了HTML页面。在本节中,我们来说说什么是HTTP请求和它的特点。
在HTTP请求中,主要有GET和POST两种方式,其主要区别在于:
- GET的信息存储在url中,比如说我们在上节看到的“?categoryId=1”。
- 而POST的信息则把信息存储在form中,比如说我们在输入登陆用户名密码的时候,不会在网址中看到这些隐私信息;当然,我们在上传大文件的时候,比如说上传一个1个G的视频,也不会把视频的信息放到url中。
另外,HTTP是一种短连接的协议,它基于TCP。为什么这么说呢,因为HTTP请求的过程其实就是:
首先,我们的浏览器通过tcp和远程web服务器的端口互相建立连接;然后发送一个指令,比如说要获取根连接(url为’/‘)的内容;再然后服务器会根据客户端(我们的浏览器)的请求返回相应的结果(如HTML文本、图片等);客户端得到了请求之后,就会将连接关闭掉,同时web服务器也关闭和客户端的连接;这样,一次HTTP请求也就完成了。
那么浏览器和web服务器是如何发送指令的呢?
在Chrome中查看HTTP请求
下面以http://nladuo.cn/test.html来作为测试页面,在输入链接的同时打开Chrome的开发者工具,调整到Network选项。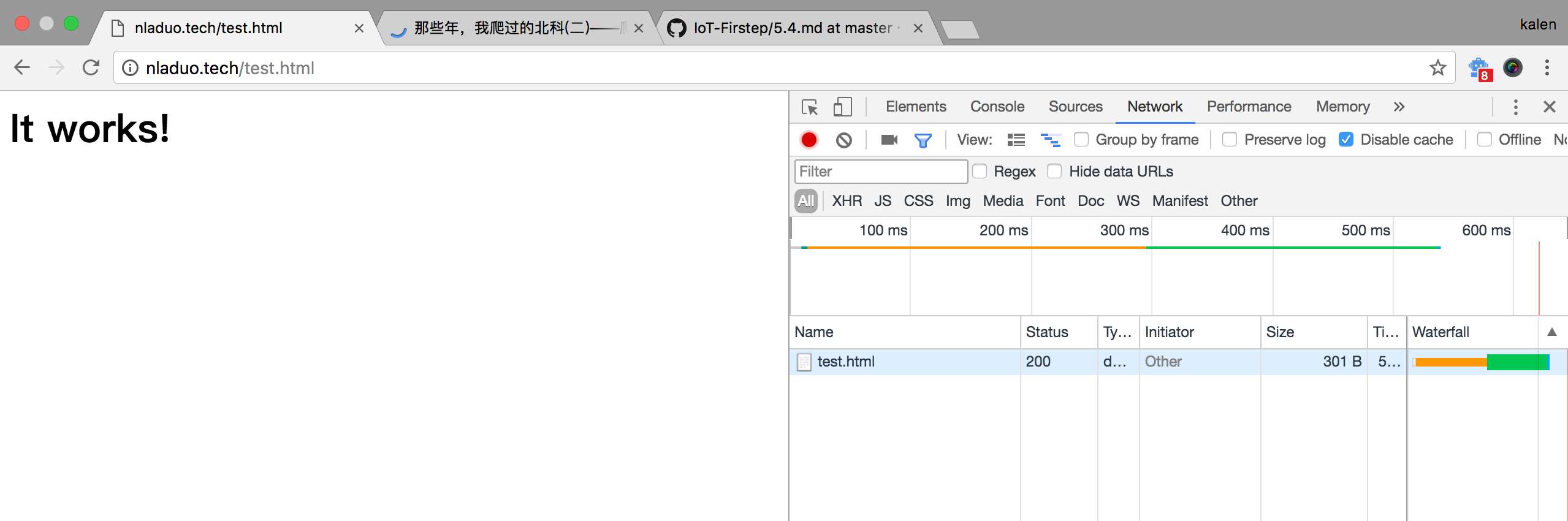
这个网页只有一个请求,那就是它的HTML,返回“It Works”。下面,我们在请求列表中点击test.html这项,可以看到服务器的相应头Requests Headers和客户端的请求头Response Headers。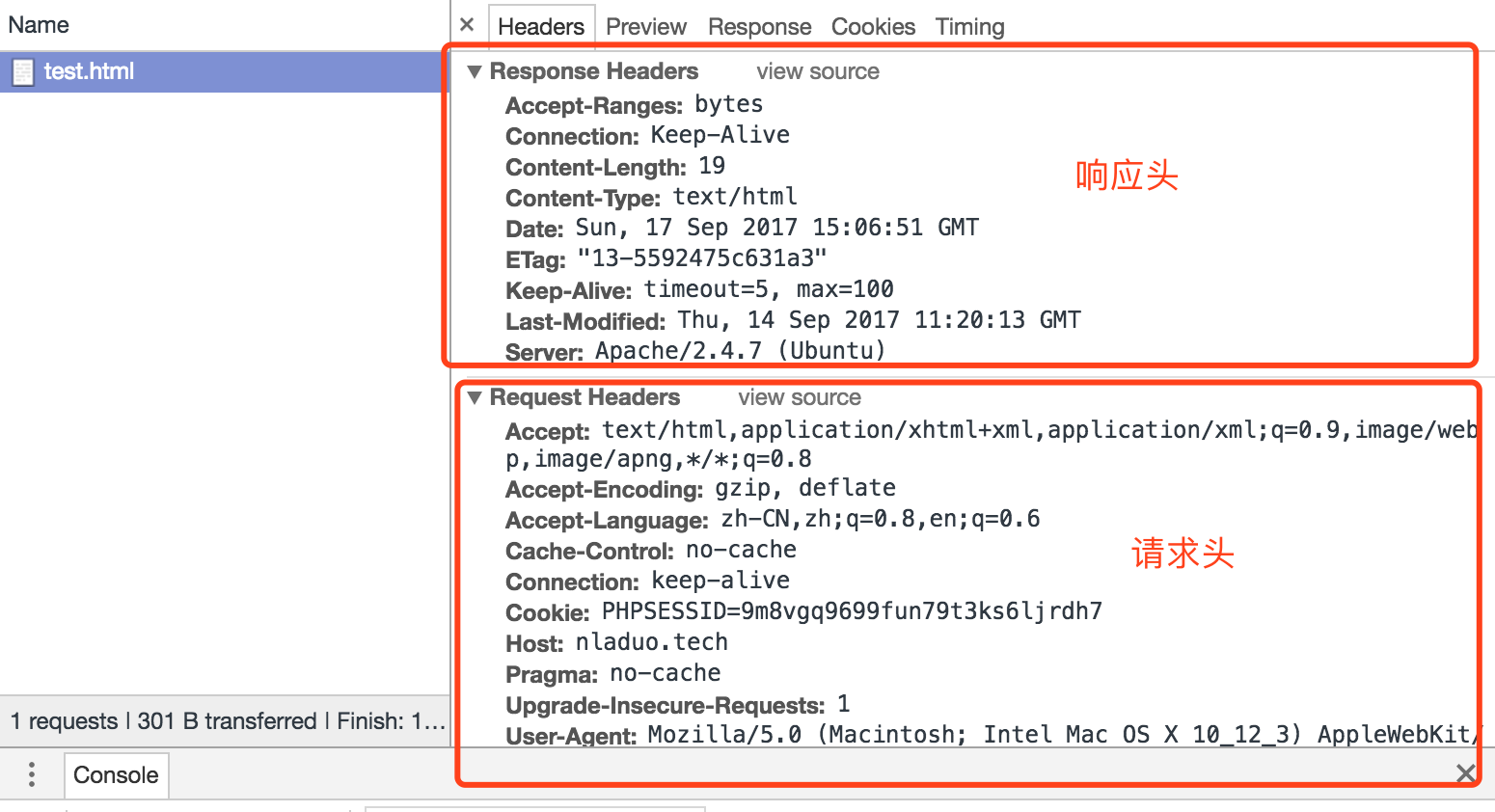
我们点击Requests Headers边上的view source可以看到原始的请求头。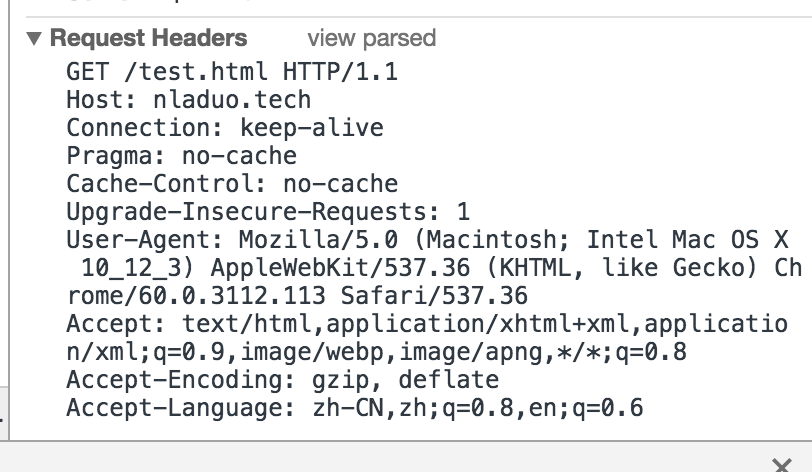
在这里面可以看到:
- 请求了nladuo.cn上面的“/test.html”这个资源,使用了HTTP1.1版本的协议,
- 请求的域名的Host为nladuo.cn
- 等等。。。
同理查看Response Headers,
可以看到:
- 使用了HTTP1.1版本的协议,返回码为200 OK
- 日期是啥
- 服务器是Apache,2.4.7(Ubuntu)版本
- 等等。。。
下面我们来使用电脑自带的tcp客户端telnet来模拟发送GET请求,看看一个GET请求的实际流程。
在电脑中使用telnet客户端
对于mac或者linux用户,可以不用进行任何配置,打开终端输入telnet即可使用。
对于Windows用户,可以在此处查看开启telnet部分。
使用telnet模拟GET请求
对于网站来说,默认开放的是80端口,比如在Network请求中的General中可以虽然没有配置,但访问的是80端口。当然,你也可以输入http://nladuo.cn:80/test.html进行访问,不过一般都不会多此一举。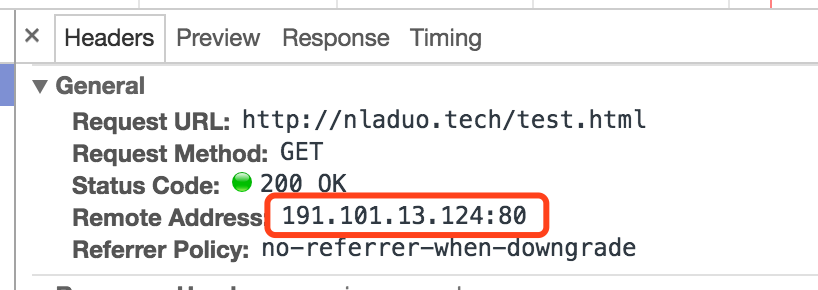
所以我们要用tcp链接nladuo.cn的80端口,使用以下命令。
1 | telnet nladuo.cn 80 |
输入之后,就可以看到nladuo.cn被解析成了ip:123.206.86.230(这里换了个服务器,所以ip变了,原为191.101.13.124)了,并建立起了tcp连接。在这时mac和linux用户就可以准备输入命令了;对于Windows系统需要首先摁下ctrl键 + ‘]’ 键进入输入模式,然后再按回车切换到显式输入模式后再输入命令。
我们像在chrome的Network看到的一样,首先我们要发一个GET请求访问/test.html资源,并使用HTTP1.1版本的协议,然后再告诉服务器我们访问的Host是nladuo.cn。之后,我们还可以告诉服务器User-Agent是啥,Accept-Encoding是啥,不过这些都不是最重要的,所以只要输入前两条即可。
1 | GET /test.html HTTP/1.1(回车) |
在这里,每输入一条后输入一个回车,在最后输入两个回车。在输入两个回车之后,等待片刻,就可以看到服务器给我们返回的信息了。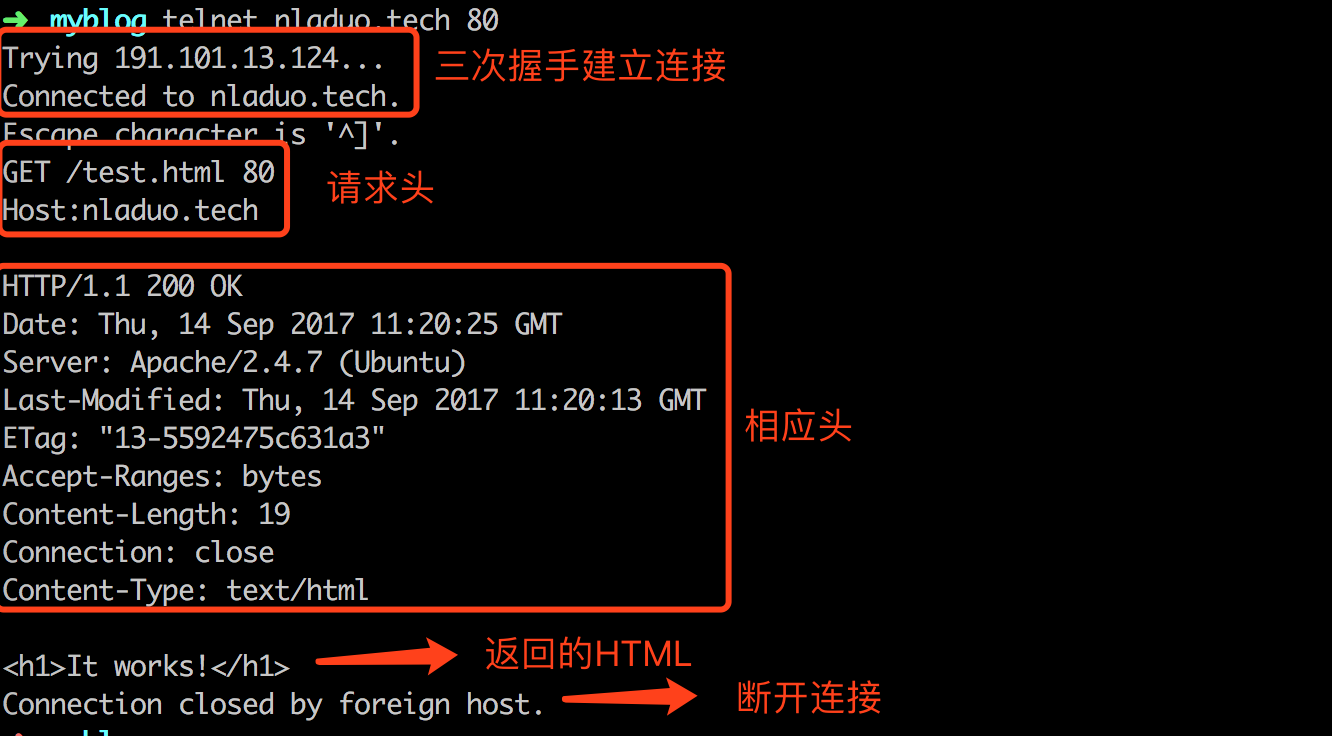
这里可以看到像之前Chrome浏览器中看到的一样,返回了200 OK、时间、服务器信息、等等….
在相应头后面的两个回车后面,可以看到返回的HTML信息:“It Works”
到这里,这次请求就已经结束了,再等待片刻,可以看到远程服务器关闭了tcp链接。一次HTTP请求也正式完成了。
模拟登陆
登陆过程发生了什么?
通过上面的利用tcp模拟http请求的案例,我们知道了客户端发送一个请求头信息,服务器返回一个相应头信息+HTML后,tcp连接就关闭了。但是我们日常使用网页中登陆网页之后,刷新之后浏览器还能记得我们登陆的信息,这是什么原理呢?
下面以一个简单的登陆页面来学习一下登陆过程中都发生了什么?登陆的链接地址为:http://nladuo.cn/crawler_lesson2/。而登陆后的隐私链接地址为:http://nladuo.cn/crawler_lesson2/private.php
首先,我们先不登录,访问一下隐私页面,注意要首先打开Network,再输入链接http://nladuo.cn/crawler_lesson2/private.php。
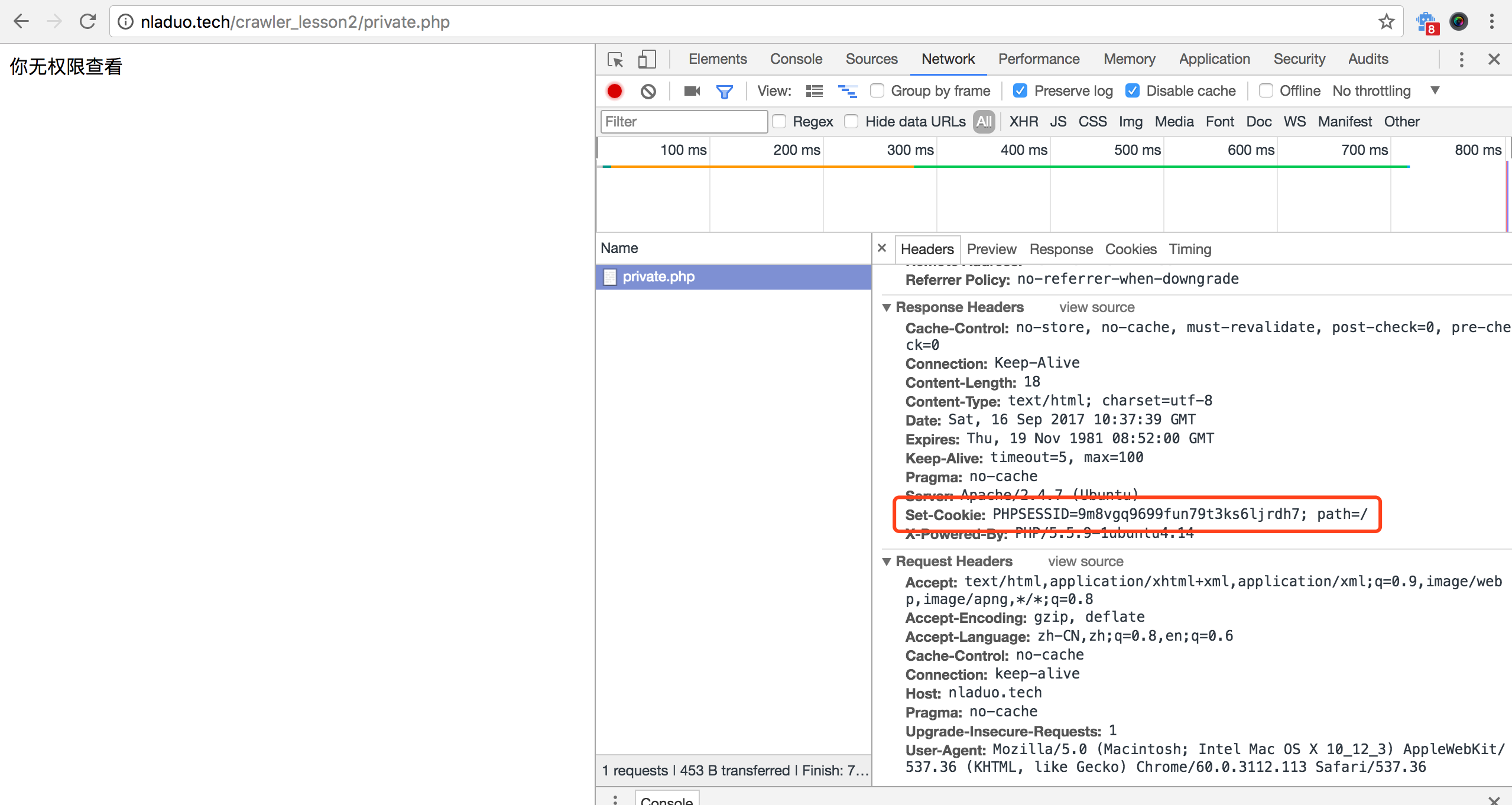
这里可以看到网页显示出了无权查看,并且Response Headers多了一个Set-Cookie字段。当然,如果你没按照我说的做,而是先输入url,显示出页面,然后再打开Network,刷新一下页面查看的话,就会看到以下的结果。
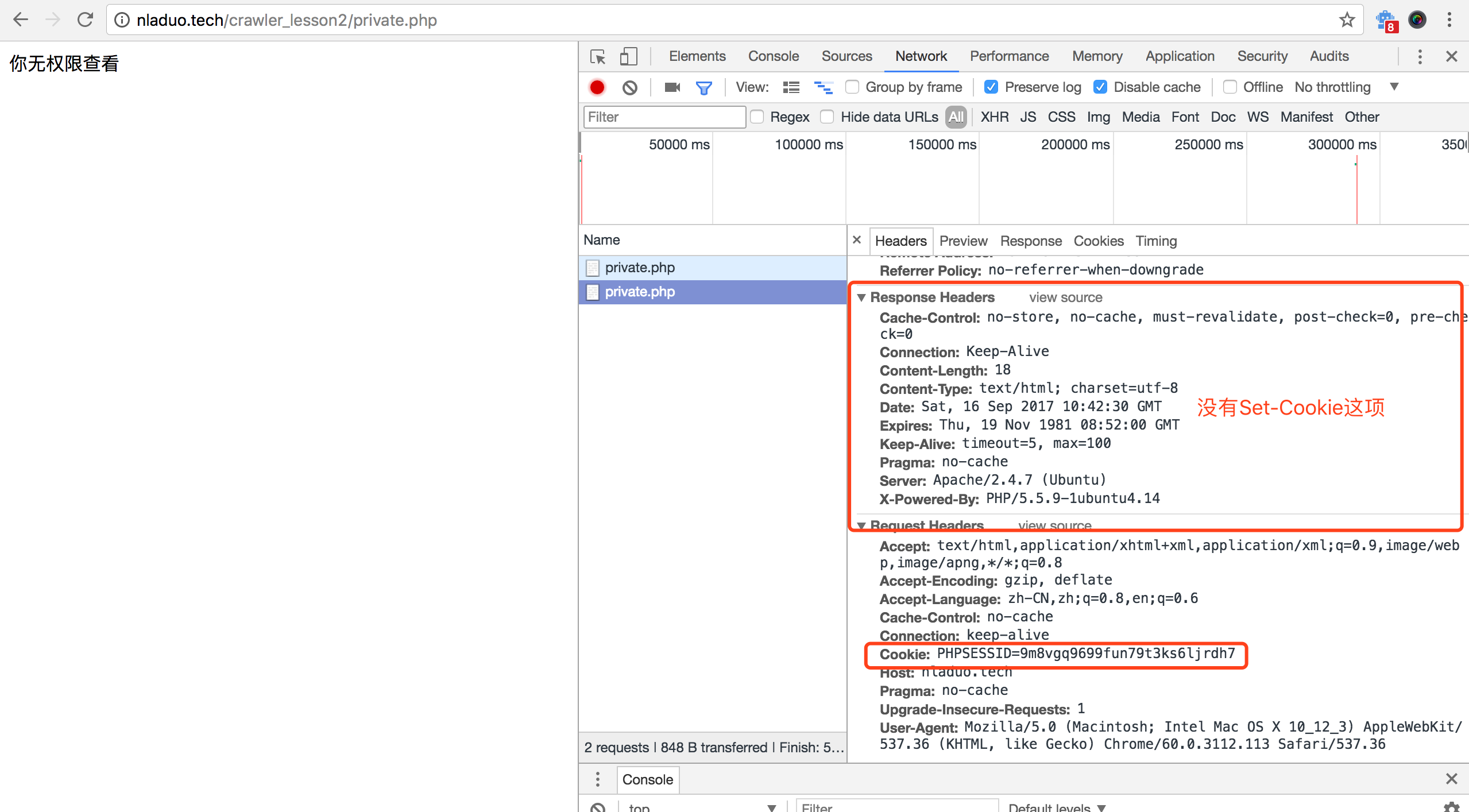
在Response Headers的Set-Cookie不见了,而Requests Headers多了一个Cookie,这两个的值还是一样的,都是“PHPSESSID=9m8vgq9699fun79t3ks6ljrdh7”。
当然,这个时候不管再刷新几次页面,Response Headers都没有出现新的Set-Cookie了;而在第一次的之后所有请求,Request Headers都会带着一个Cookie。比如我们这里查看登陆页面,http://nladuo.cn/crawler_lesson2/,也带了这个Cookie。
这里可以先带着疑问,我们现在知道,Set-Cookie只执行一次,由服务器返回;在此之后,浏览器会保存Set-Cookie保存的值,每次访问这个域的内容都会带着Set-Cookie的值,并把他放到Cookie字段里。
接下来,我们尝试一下登陆,这里,用户名和密码都默认为nladuo,我们只要在输入框输入nladuo即可。点击登陆后,我们可以看到这里发了一个POST请求,显示出了“登陆成功”。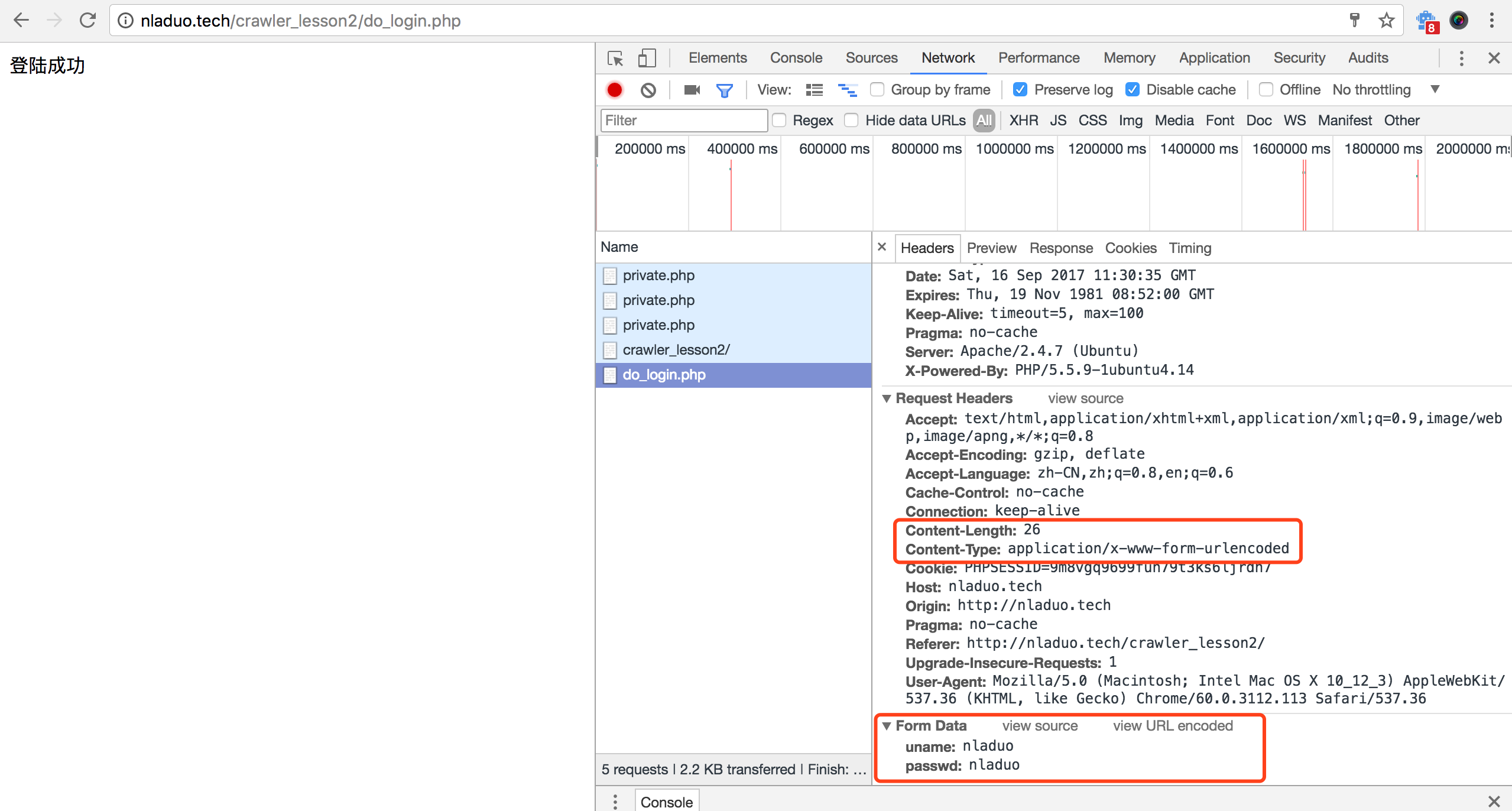
相比GET而言,POST的请求头中多了Content-Type和Content-Length两个字段,因为这次是把数据放到了Form Data中,而不是在url里了。这里Content-Length就是发送字节的长度,Content-Type则是发送的类型,这里会把表单中的字段转换成键值对,如uname:nladuo,passwd=nladuo转换为uname=nladuo&passwd=nladuo,这样正好也是26个字符。
当然,这里,我们也可以用Telnet模拟POST请求,读者可以看一下,这里就不多说了。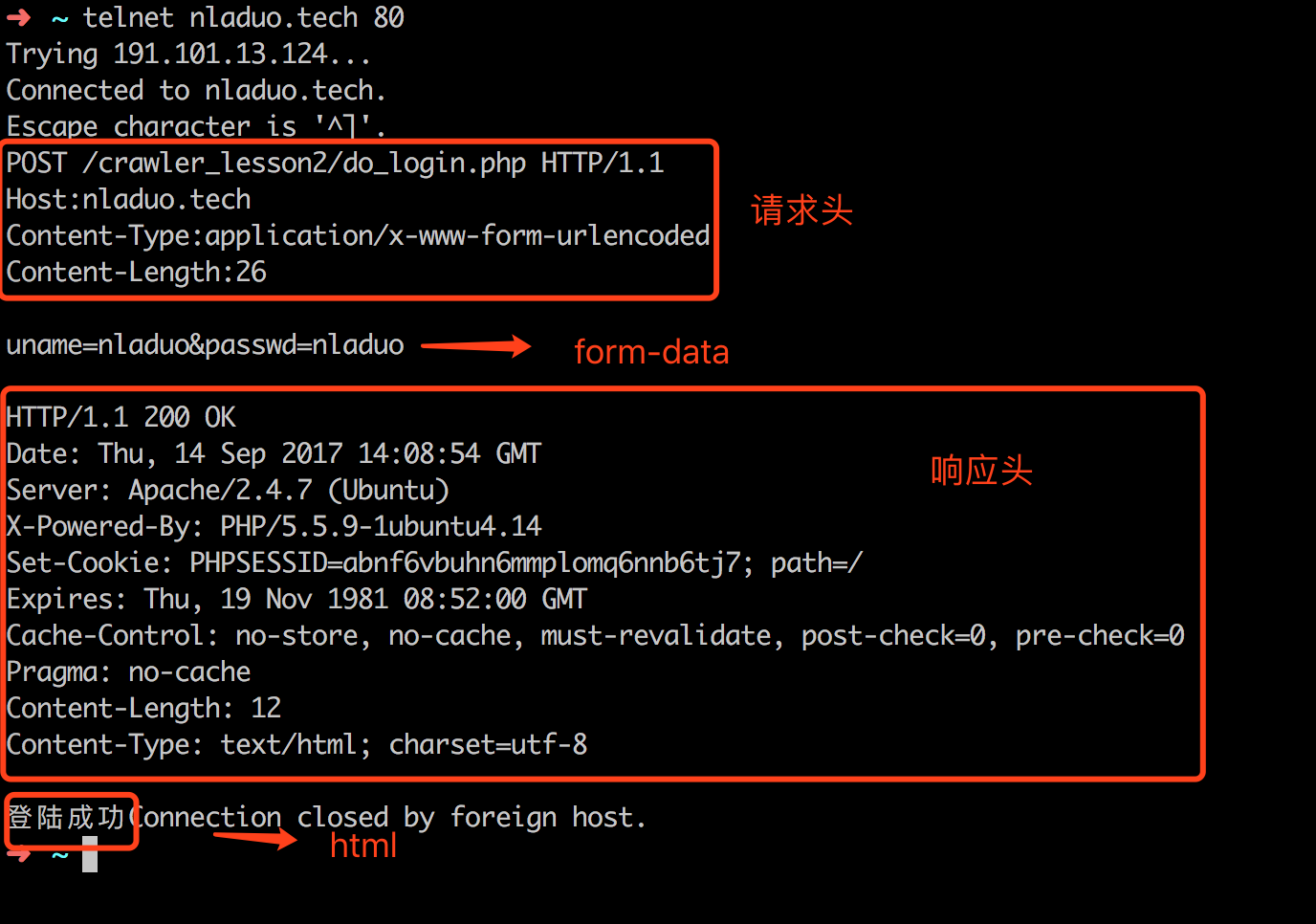
下面,我们再看一下Cookie,可以发现这里Cookie没有变,还是 “PHPSESSID=9m8vgq9699fun79t3ks6ljrdh7”。
Cookie与Session
看到这里,带着疑问,可以引出Cookie和Session的概念了。
我们上面看到的Cookie是一种客户端的技术,而Session则是服务端的技术。登陆的过程其实就是一个会话开始的时候,服务器给客户端一个ID,如上面看到的Set-Cookie,这其实就代表会话的开始,而当浏览器关闭后,一次会话也就结束了。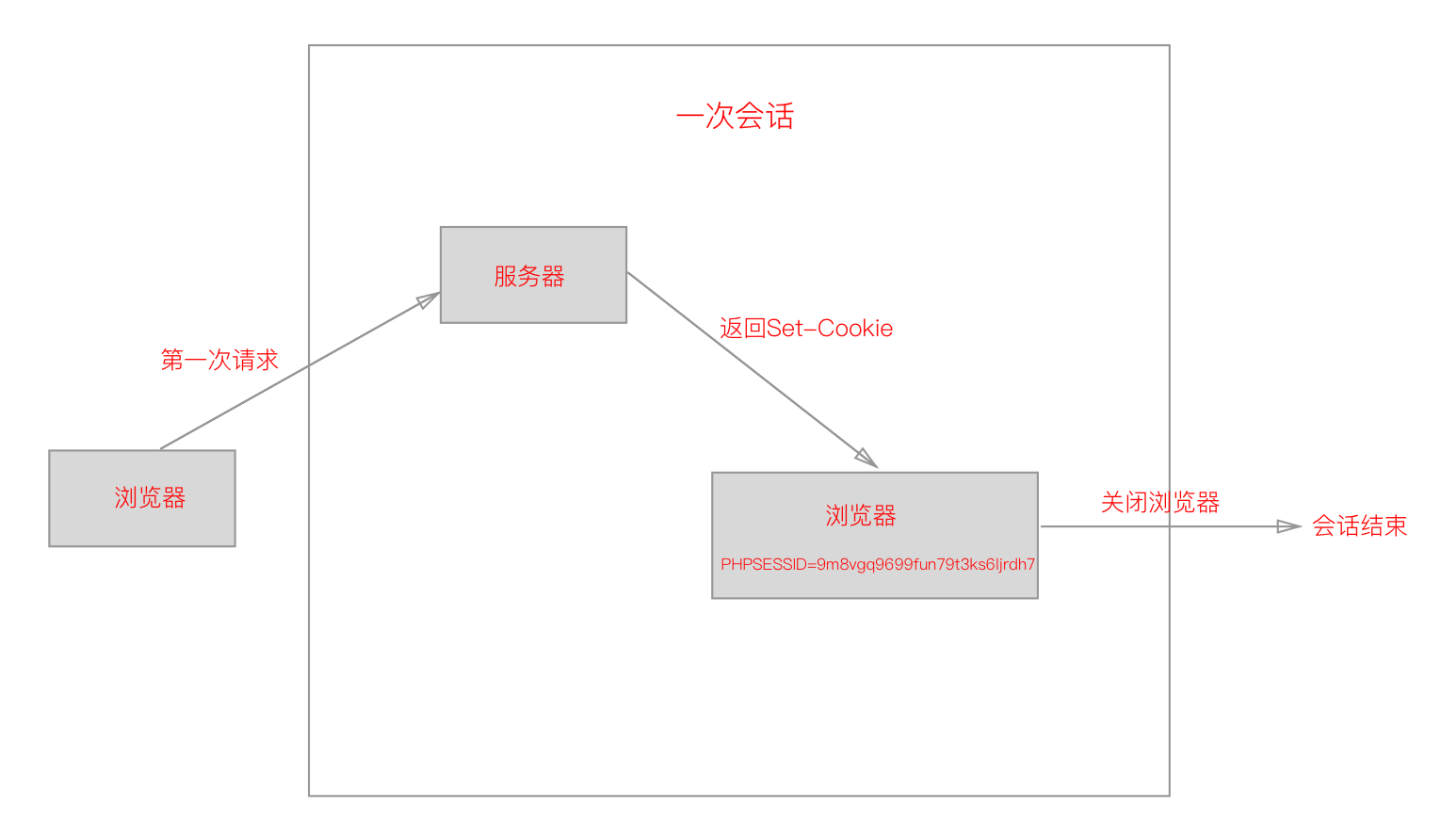
在一次会话中,用户的状态保存在服务器中,而客户端是保存一个会话ID,所以当我们在没登陆的时候请求http://nladuo.cn/crawler_lesson2/private.php页面时,服务器会在缓存数据库里的PHPSESSID这张表查找id为9m8vgq9699fun79t3ks6ljrdh7的字段,判断用户是否登陆了,然后根据查询的结果来返回不同的页面。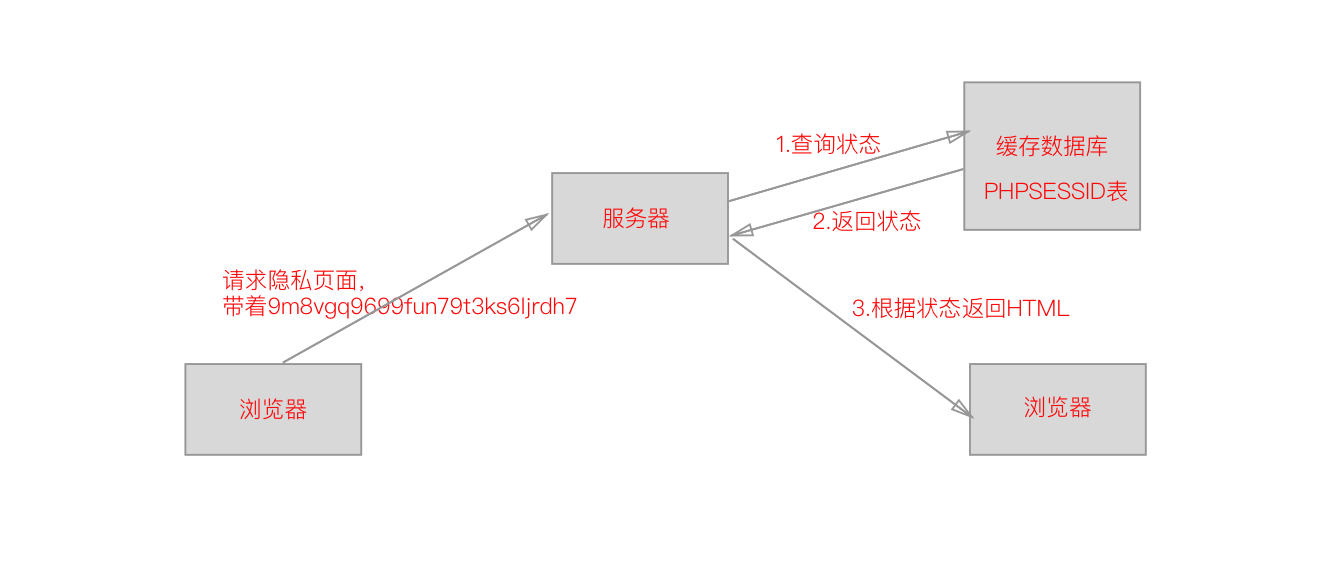
比如,我们在没有登陆前,缓存服务器中PHPSESSID中9m8vgq9699fun79t3ks6ljrdh7的is_login字段是NULL,所以服务器查询到is_login是空的,所以不给用户看隐私页面。当我们登陆的时候,如果用户名密码正确,服务器就会给缓存服务器上的9m8vgq9699fun79t3ks6ljrdh7字段的is_login设置为True,当用户下次请求隐私页面的时候,就可以看到正确的返回结果了。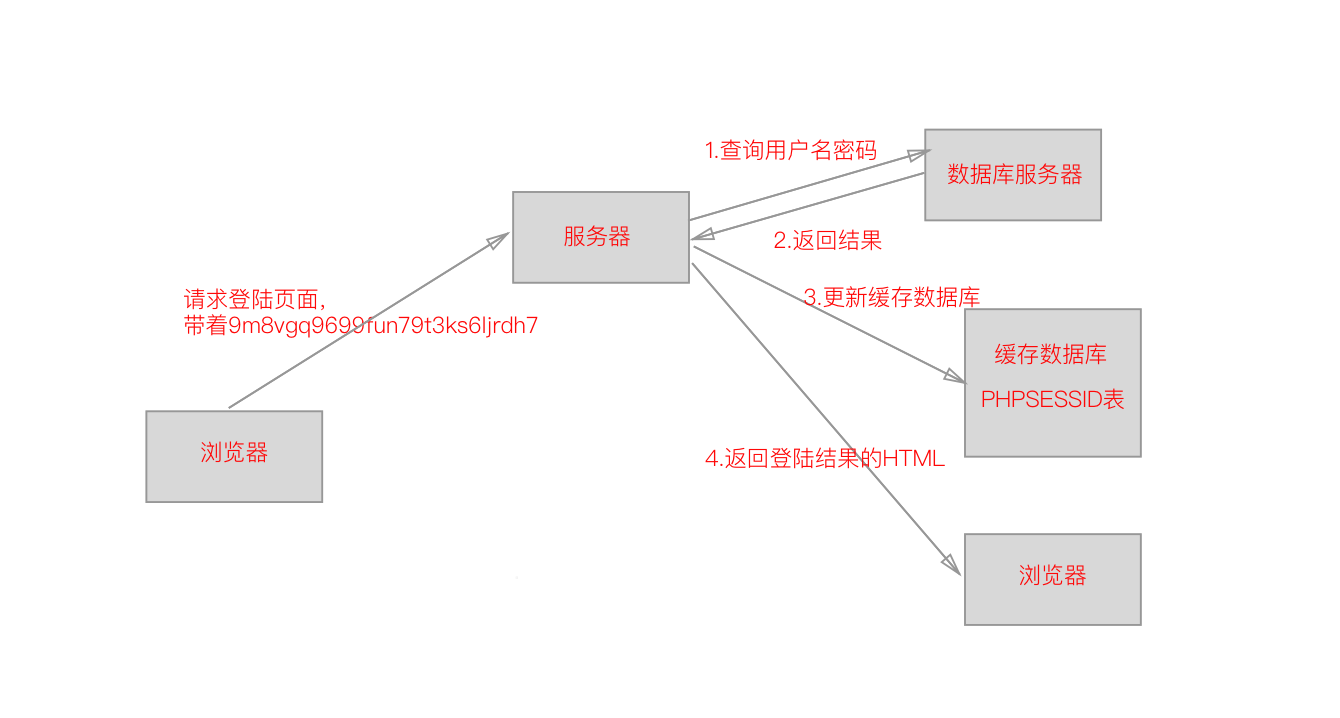
使用Cookie模拟登陆
通过上面的学习,我们知道了如何进行登录,下面我们用代码模拟一下这个步骤:1.首先登陆,2.保存Cookie,3.带着Cookie请求隐私页面
1 | # 1. 先登陆 |
运行代码,可以看到这里登陆成功,返回了隐私页面。
使用requests.session模拟登陆
不过,上面的方式手动管理Cookie总感觉有些麻烦,Requests库给我提供了一个更方便的对象:requests.session,它可以像浏览器一样记录我们的会话中的Cookie。
1 | import requests |
现在,我们的代码中的流程就像人用浏览器的操作的过程一样了,登陆一下,直接请求隐私页面就好了。
运行代码后,可以看到同样的正确结果。