介绍
在前面我们介绍了如何编写爬虫,但是我们的爬虫并没有把数据保存下来,只是简单的显示在控制台中。在本节,我们将简单学习一下数据库,以及如何在python中操作数据库。
最后,我们将修改上一节的爬虫框架,使其支持数据库插入。
注:如果读者已经了解mongodb,可以直接跳到最后一个部分:修改我们的爬虫框架。
MongoDB数据库介绍
数据库其实也就是数据仓库,用来存储数据的地方。以下是数据库在维基百科中的解释:
数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
没有数据库,我们可能会把爬取的数据存成一个json文件,插入的时候可能要先把整个json序列化成python的列表,然后再进行增删改查,而且数据操作的效率可能会比较低。有了数据库,数据库会给我们提供方便的API接口,可以很容易对数据进行增删改查操作,并且高效。
MongoDB是一种文档型数据库,它属于非关系型数据库。
MongoDB安装
如果没有安装过MongoDB,需要先对mongodb进行一下安装。
下载MongoDB
MongoDB有商业版也有社区版本,我们下载免费的社区版本就好了。可以在此处https://www.mongodb.com/download-center/community看到各种操作系统的MongoDB安装包。
我们可以选择一款适合自己的操作系统的进行下载安装。下面我们分别以Mac和Windows系统举例来进行MongoDB的安装。
Mac版本安装与启动
下载安装包
首先我们下载最新版本(4.0.4版本)的mongodb的包,可以看到下载下来是一个tgz的解压文件。
然后我们对tgz文件进行解压, 并进入到解压后的目录
1 | tar zvxf mongodb-osx-ssl-x86_64-4.0.4.tgz |
进入目录后,我们可以看到有一个bin目录文件,这里面就是mongodb的各种脚本了。
启动MongoDB服务器
然后我们需要创建数据存放的目录,mongodb数据默认存放的路径是/data/db,如果这个目录不存在的话,需要自己创建。确保数据创建后,通过mongod命令即可启动mongodb服务。
1 | ./bin/mongod # 启动mongodb服务 |
如果不想用/data/db这个路径的话,可以通过--dbpath参数设置想要存放的位置。
1 | mkdir test |
使用MongoDB客户端
接下来我们测测能不能连上服务器,这里可以用mongodb自带的客户端:mongo命令。在终端中输入以下命令,尝试连接mongodb服务。
1 | ./bin/mongo |
如果输入命令后,成功看到左下角有个代输入的光标,就说明安装成功了。
Windows安装与启动
下载安装包
首先我们下载最新版本(4.0.4版本)的mongodb的包,我们这个选择zip安装包。
下载后进行解压,然后进入解压后的目录,可以看到有一个bin文件夹,这里面就是mongodb的各种脚本。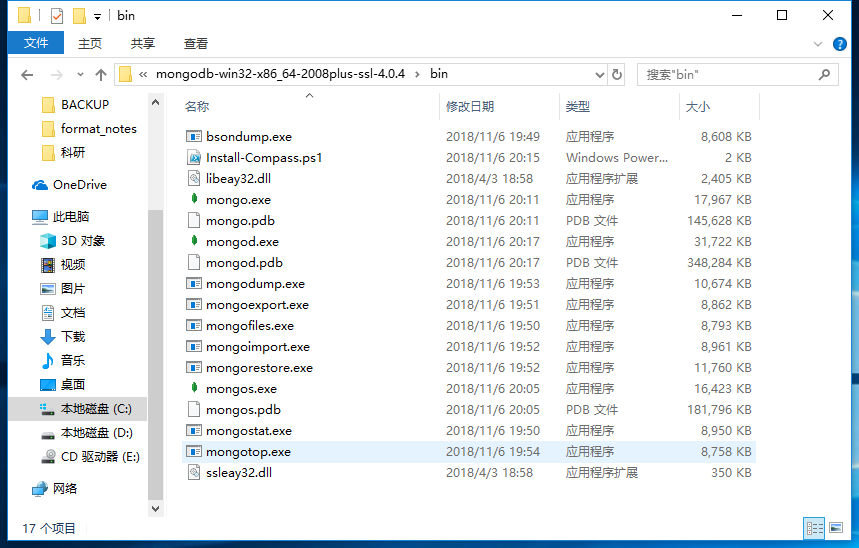
启动MongoDB服务器
然后我们需要创建数据存放的目录,mongodb数据默认存放的路径是C:\data\db,如果这个目录不存在的话,需要自己创建。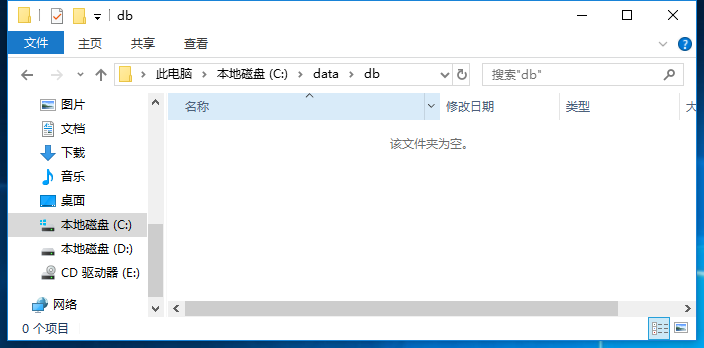
确保数据创建后,通过mongod.exe命令即可启动mongodb服务。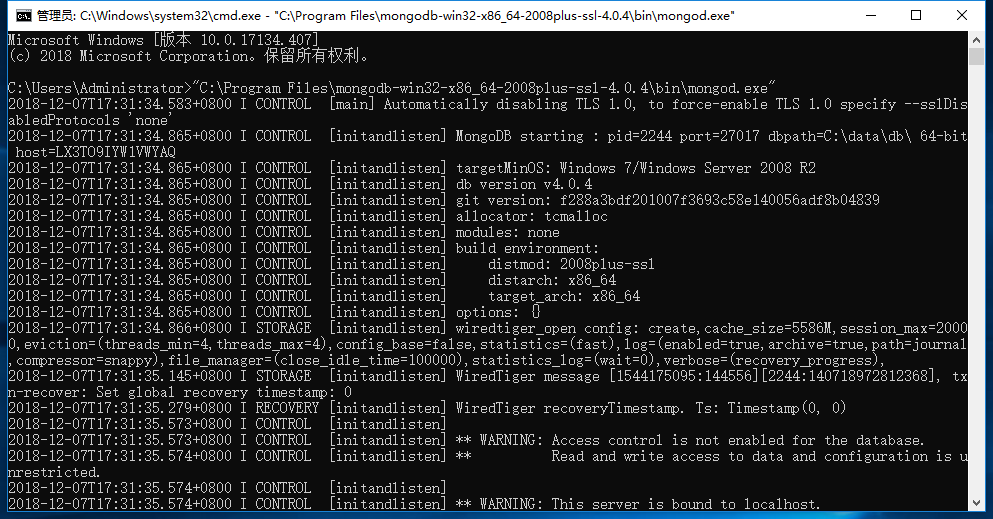
如果不想用C:\data\db这个路径的话,可以通过--dbpath参数设置想要存放的位置。
使用MongoDB客户端
接下来我们测测能不能连上服务器,这里可以用mongodb自带的客户端。在终端中运行mongo.exe,尝试连接mongodb服务。
如果运行后,成功看到左下角有个代输入的光标,就说明安装成功了。
MongoDB的一些概念
MongoDB以BSON格式的文档(Documents)形式存储。Databases中包含集合(Collections),集合(Collections)中存储文档(Documents)。接下来我们简单了解一下这几个概念。
Databases: 数据库
Databases是数据库,我们一般会把不同的项目划分成不同的数据库。
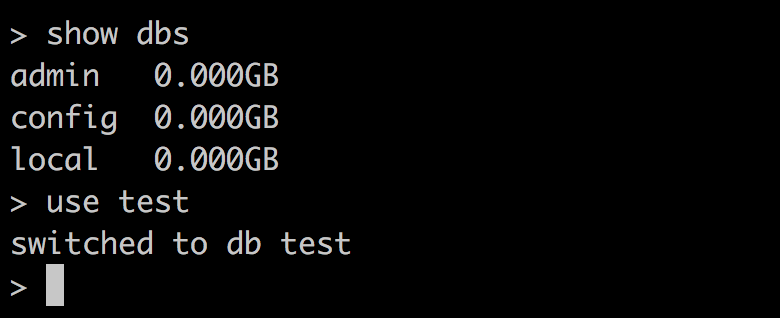
我们可以使用show dbs查看已有的数据库,使用use db_name进入某个数据库。下面是我们进入test数据库的截图。
Collections: 集合
Collections是集合,一个项目中,也会有不同格式的数据。我们一般会将同一种类型的数据放在一个集合里面。比如说我们开发网站有新闻,可能会创建一个news集合;也需要有用户,再创建一个user集合。
集合的概念就如同关系型数据库里面的表一样。
Documents: 文档
Documents是文档,文档是由field和value对的结构组成,如下结构。
1 | { |
其中field名是个字符串,而value值可以是任何BSON数据类型,包括:其他document,数字,和document数组。
在MongoDB中集合不需要创建,直接使用就可以,同理数据库也不需要创建,直接使用use就可以。
下面我们在test数据库下面的news集合中插入一条数据看看。
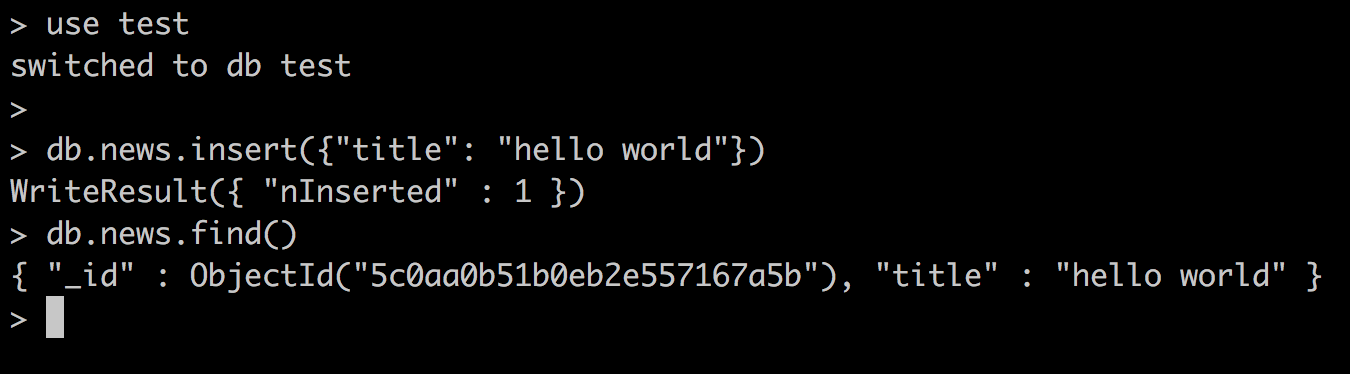
这里可以看到我们的数据如下:
1 | { |
除了我们插入的title字段外,还有一个_id字段,这是一个索引字段,作为一个文档的唯一标识。我们可以通过_id对某一个文档进行查找。
pymongo的使用
我们这里是一个python的教程,所以主要要学习一下如何在python中操作mongodb。在了解前,先安装一下mongodb的python包:pymongo。
1 | pip install pymongo |
连接数据库
在数据库操作前,我们首先要连接数据库。这里连接数据库的代码如下:
1 | import pymongo |
上面我们连接了我们本地的mongodb数据库,mongodb默认使用的端口是27017。当我们不使用数据库的时候,记得要把数据库的连接关闭掉。
1 | client.close() # 关闭数据库 |
接下来,我们就可以选择我们需要操作的数据库和集合了。可以使用字典或者点的方式拿到数据库和集合的实例。
1 | # 使用字典的方式 |
这里我们使用test数据库下面的items集合进行示意。
插入数据
接下来,我们先来插入几条数据到啊items集合。这里我们先定义一个list_items函数用来列出items集合中所有的数据来。其实就是调用find方法,就可以直接找出所有items下的数据了,返回对象是个迭代器,可以通过for...in...拿到里面所有的元素。
1 | def list_items(): |
插入数据也很简单,和在mongo命令使用的基本上是一样的。就是一个insert方法,插入一个字典即可。
1 | # 增 |
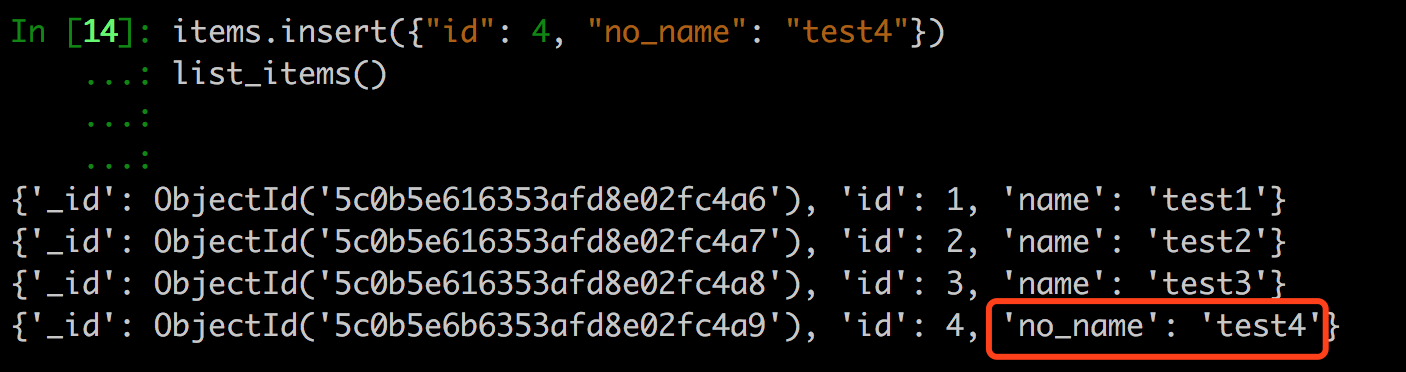
mongodb一个集合中的数据可以不完全一样,比如说可能有的文档有name字段,而有的文档没有name字段。不过我们最好不要这么做,虽然mongodb允许,因为这样可能会让自己容易混乱。
1 | items.insert({"id": 4, "no_name": "test4"}) |
删除数据
在mongodb中删除数据直接使用remove方法就好了,remove的参数就是要删除元素的条件,比如下面是删除id为1的数据。
1 | print("删除id为1") |
不过上面演示的id其实是假的id,因为它可以不是唯一的。在mongodb中使用的_id字段作为索引,这个索引是自动创建的,它是一个ObjectId类型。我们可以通过下面的代码操作一个唯一的文档。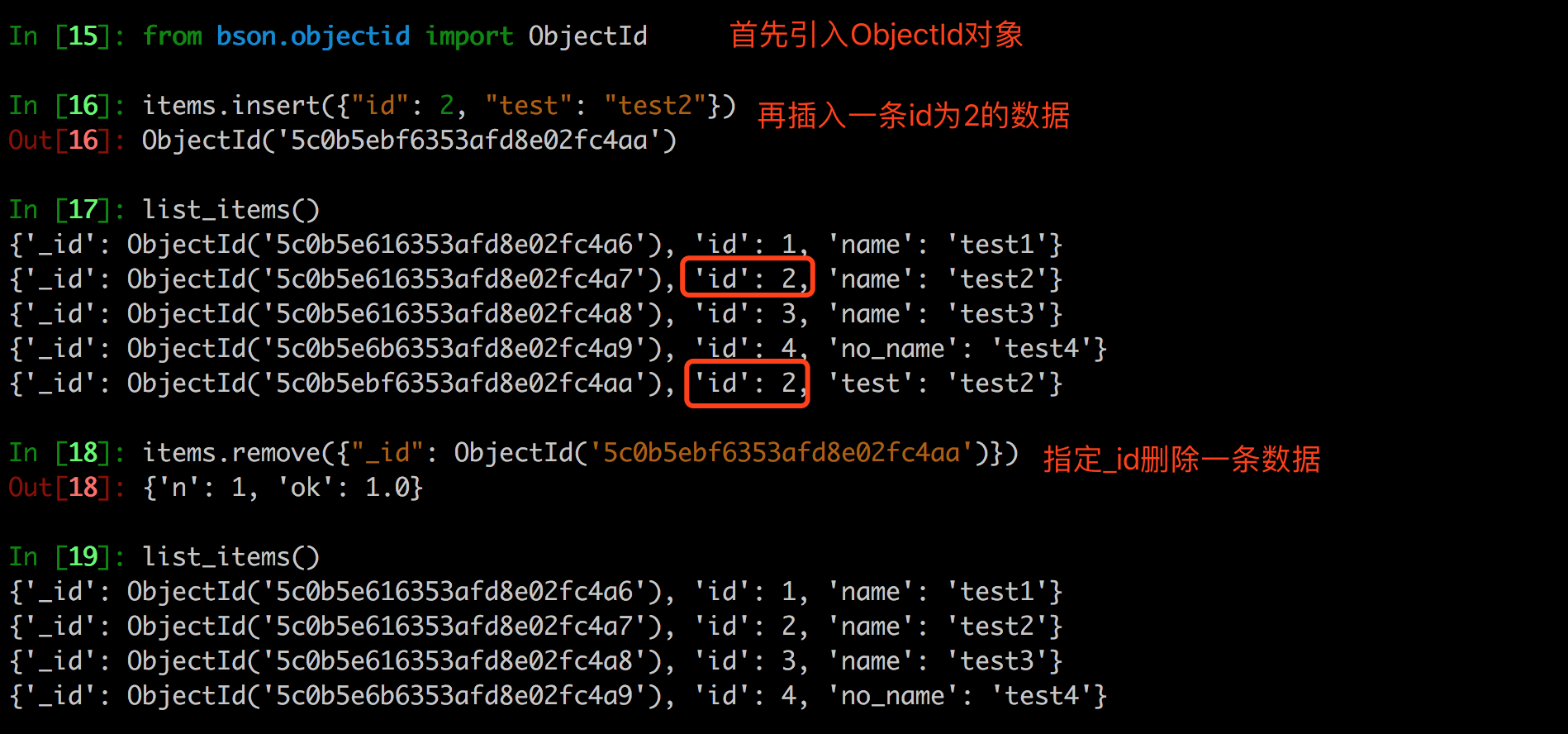
更新数据
更新数据的话是用的update方法,update方法接受多个参数,主要有三个。
- 第一个参数:spec,指定要更新的数据。
- 第二个参数:document,要修改的数据。
- 第三个参数:multi,是否要更新多条数据,默认为False,也就是说默认只更新一条数据。
我们先来看看更新一条数据。
1 | print("修改id为2的name") |
这里第二个参数如下:
1 | { |
这里可以看到我们修改了id为2的name字段。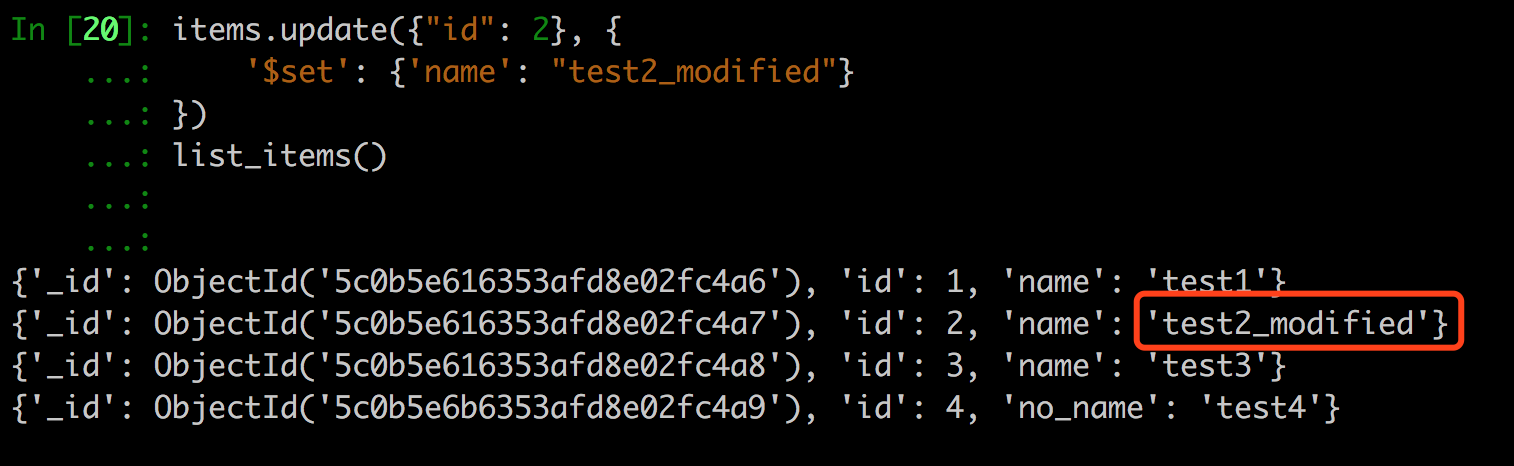
接下来再来试试更新多条数据。
1 | print("修改所有数据,添加一个title字段") |
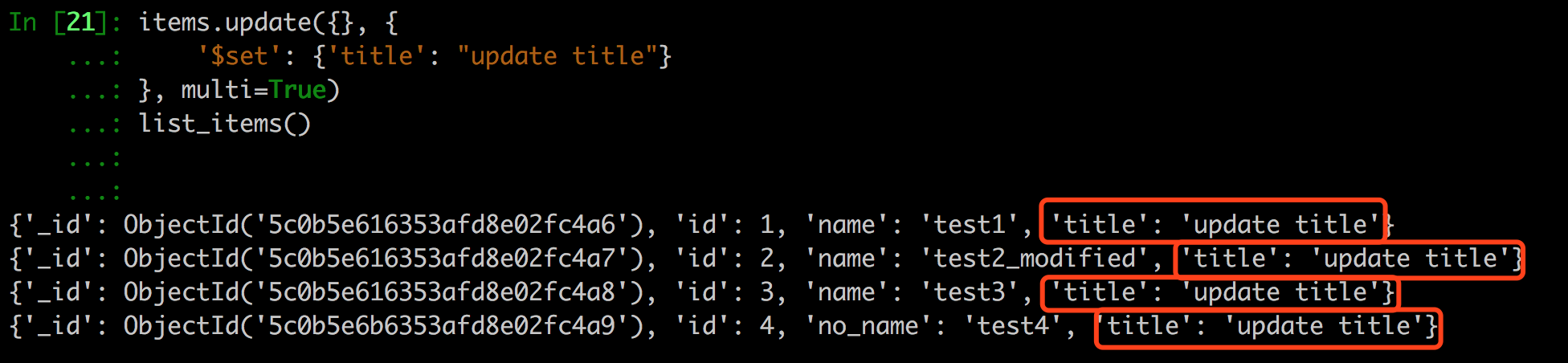
查找数据
最后是查找数据了,这里可以通过find方法找到多条数据,find_one方法找到一条数据。对于find_one方法,如果没有找到的话,会返回None。
1 | print("查找id为2") |

修改我们的爬虫框架
关于数据库的介绍就到这里了,如果读者对mongodb操作感兴趣可以查阅更多相关资料。
下面,我们把mongodb数据融入到我们的爬虫框架中,并通过框架把上一节的爬虫爬取的内容存入数据库中。这里其实在框架里面添加一行代码即可。
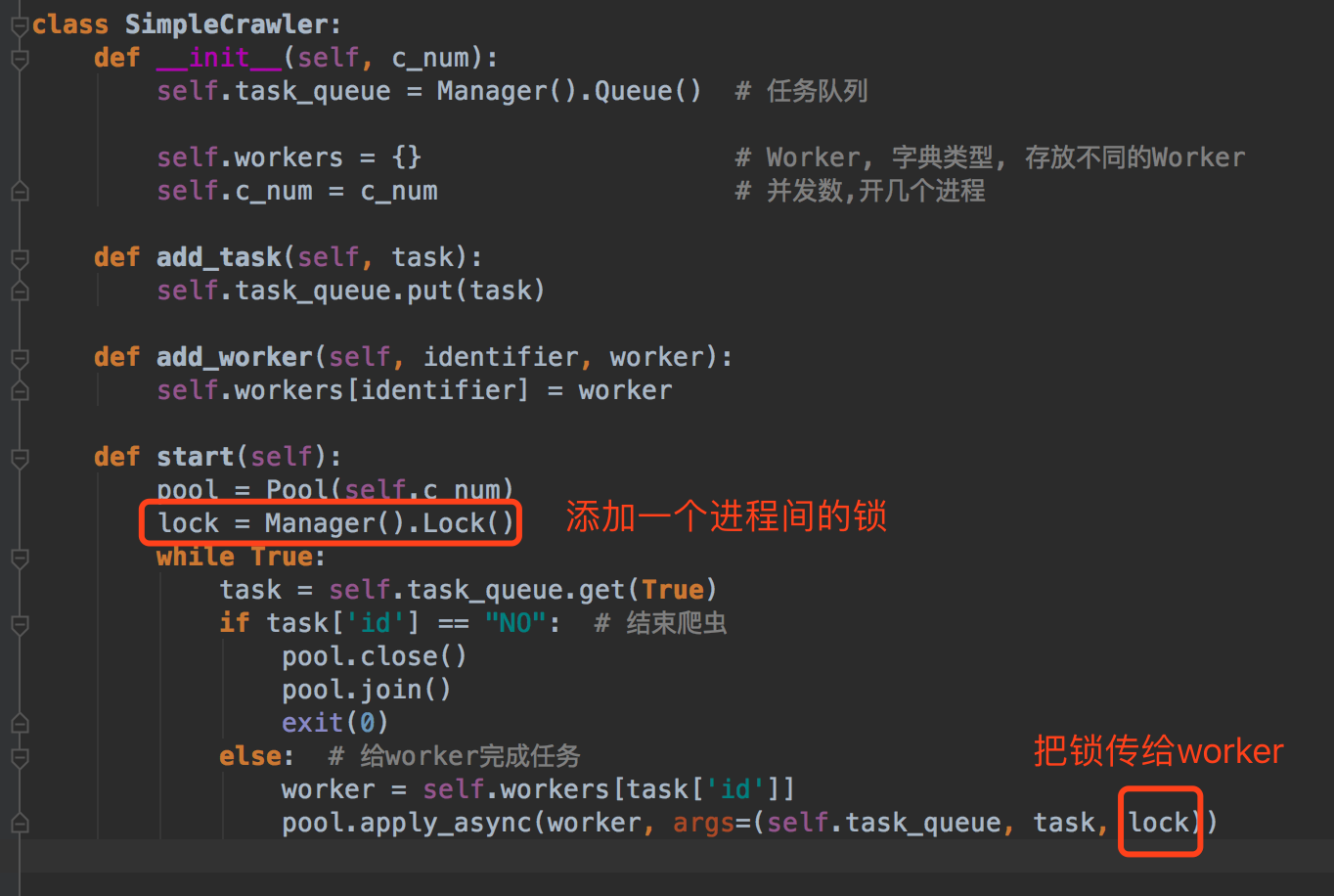
进程间锁
考虑一个场景,我们在爬取数据的时候,肯定不希望有重复的数据添加到数据库里面,所以我们可能需要在插入数据库之前,判断一下这条数据有没有插入过。判断插入再插入的代码如下:
1 | insert_id = 2 |
但是,这里考虑一个场景,在多进程操作时候,我们两个进程:进程1和进程2,同时使得insert_id为2。这个时候数据都还没有插入,所以find_one之后得到的都是None。但是下一时刻,进程1先插入了数据,这个时候进程2因为先前进行find_one也得到的是None,所以就会插入两条id为2的数据。
虽然这个可能性非常低,但是不能排除。这里我们使用锁就好了。
1 | lock = Manager().Lock() |
在操作插入代码块的时候,进程1和进程2要获取锁,才能执行。比如说这个时候进程1拿到锁了,进程2没有拿到,那么进程2就会等待。进程1把步骤①和步骤②都完成之后,才会释放锁。进程②拿到锁,再进行步骤①和步骤②。
这样就不会出现上面的那种情况了。
所以,我们可以在我们的框架中也添加一个这样的锁。我们需要再我们的框架中添加这个锁,然后把这个锁传给worker,worker在需要数据库操作的时候再使用这个锁就好了。
爬虫实践
接下来我们需要对上一节的worker进行稍微修改,首先添加lock参数。然后再把数据插入到数据库中。

之后运行爬虫,使用mongo客户端检验一下爬取的数据是否存入数据库。
在MongoDB自带的客户端中写代码查看有的时候有些麻烦,读者也可以装一个MongoDB的可视化客户端,我这里用的是Robo 3T,也是有免费版本的。
补充说明
我们上面的操作其实相当于同一时间只会操作一条数据,方式比较简单粗暴。实际上,mongodb是可以支持多连接的,也就是说可以并发操作。
读者感兴趣的话,可以考虑在框架中添加一个pipeline,在pipeline中构建多个mongodb数据库的连接,用于专门操作数据库数据。