之前学过的信息检索都忘得差不多了,这篇文章用来总结和记录一些信息检索(IR)领域的概念和基础知识。
总览
信息检索其实就是有一个查询和已有的文档数据集。给一个查询query,从数据库中的文档中找出相关的document文档来。
笔记目录如下:
- 布尔检索
- 向量空间模型
- 信息检索的评价
- 排序学习
布尔检索
布尔检索的查询,是指利用 AND, OR 或者 NOT操作符将词项连接起来的查询。
比如说我们的目标是:在《莎士比亚全集》找出包含Brutus AND Caesar ,同时又不包含Calpurnia的章节(文档)来。
词项-文档关联矩阵
这里肯定不能将文档扫描一遍,而是可以通过一个一个词项文档关联矩阵来进行检索。
给定查询Brutus AND Caesar AND NOT Calpurnia, 求解方法如下:
- 取出三个词项对应的行向量 ,并对Calpurnia 的行向量求反,最后按位进行与操作
- 110100 AND 110111 AND 101111 = 100100.
第一篇文档和第四篇文档是我们的查询结果。
倒排索引
随着词项的增多,会导致关联矩阵会变得非常稀疏。一般来说词表大小会有好几万甚至几十万,而一篇文章中一般也就几百几千个词,所以会有数据很多为0。
倒排索引(inverted index)其实也就是词项-文档关联矩阵,但是进行了压缩,使用更少的空间进行存储。其形式如下:
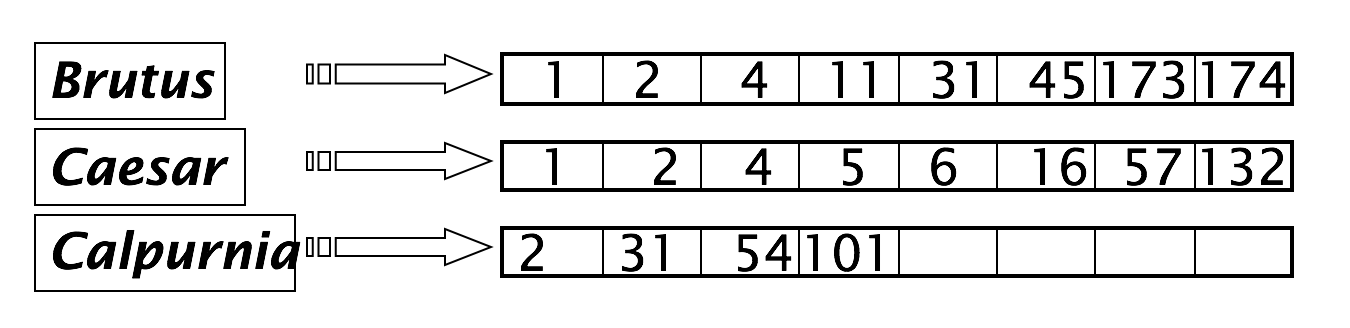
相当于原先的存储空间是:词项个数文档个数。现在是:词项个数文档平均长度。
向量空间模型
在布尔模型中,只讨论了词是不是出现的问题,这里的假设是每个词都是同等重要的。但其实并不是每个词重要程度。所以这里需要对不同的词引入权重的概念。
TF-IDF
TF:term frequency,词项t在文档中出现的次数。出现的越多就越重要。
IDF:inverse document frequency。document frequency是指在整个文档集出现的次数,出现的越少,说明这个词在文档越重要,也就是“物以稀为贵”。
所以TF-IDF其实就是:
$$ tf-idf_{t,d} = tf_{t,d} \times idf_{t} $$
评分计算
以上的TF-IDF是针对document的一个term进行的。
对于一个文档来说,把每个term都计算tf-idf可以得到文档的向量表示$$\vec{V}(d)$$,同理也可以得到查询q的向量表示$$\vec{V}(q)$$,这也就是向量空间模型。
我们在搜索中,其实目标就是找出查询向量$$\vec{V}(q)$$和每个文档向量$$\vec{V}(d)$$的相似度,然后得到一个排序,得分高的排在前面,得分低的在后面。
$$ score(q,d)=\frac{\vec{V}(q) \cdot \vec{V}(d)}{|\vec{V}(q)| \cdot |\vec{V}(d)|} $$
Okapi BM25
BM25是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法,再用简单的话来描述下BM25算法:我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词,然后单词的分数由3部分组成:
- 单词和D之间的相关性
- 单词和query之间的相关性
- 每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。
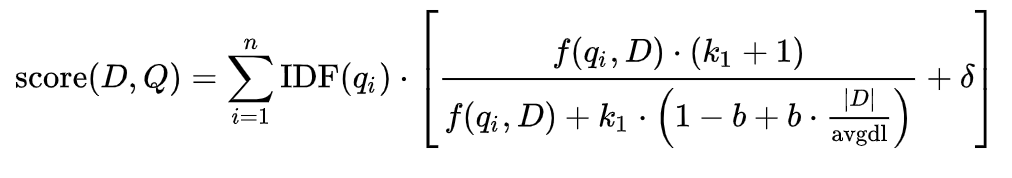
信息检索的评价
MAP
- 平均正确率(Average Precision, AP):对不同召回率点上的正确率进行平均
- Mean Average Precision:对所有查询的AP求宏平均。(宏平均:对每个查询求出某个指标,然后对这些指标进行算术平均)
系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。
NDCG
每个文档不仅仅只有相关和不相关两种情况,而是有相关度级别,比如0,1,2,3,4(bad、fair、good、excellent、perfect)。我们可以假设,对于返回结果:
- 相关度级别越高的结果越多越好
- 相关度级别越高的结果越靠前越好
Normalized Discounted Cumulative Gain: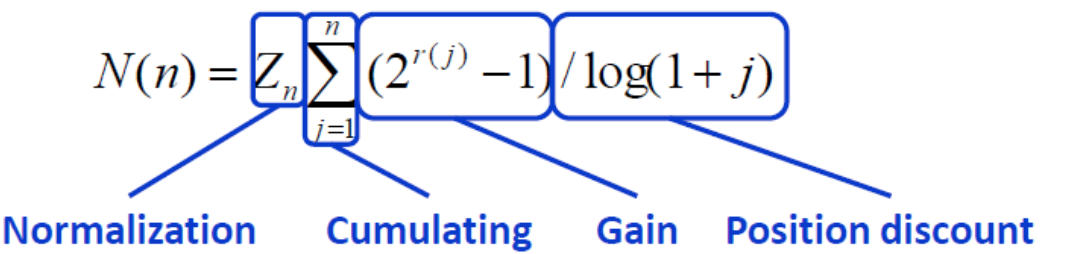
排序学习(Learning to Rank)
排序问题就是使用一个模型 $$f(q,d)$$来对该query下的documents进行排序。传统的Learning to Rank(LTR)模型有三种方法:
Pointwise approach
通过ML的方法来学习查询-文档对的得分:f(query,document)。比如说不相关的document打1-10分,相关的document打10-50分。然后根据得分来排序。
Pairwise approach
在检索中,其实并不需要计算得分。我们只要知道两个文档的序就好了。所以只要知道f(query,doc1)和f(query, doc2)哪个排在哪个前面就好了。我们知道两两的排序关系,也可以得到最终的排序结果。
listwise approach
Listwise与上述两种方法不同,它是将每个查询对应的所有搜索结果列表作为一个训练样例。
Reference
- ChristopherD.Manning, PrabhakarRaghavan, HinrichSchutze,等. 信息检索导论[J]. 2010.
- https://www.zybuluo.com/zhuanxu/note/974675
- https://www.cnblogs.com/eyeszjwang/articles/2368087.html